Writing an operating system is no easy feat, but it is extremely rewarding and helps polish the skills of even the most accomplished programmer. Operating systems are beautiful and complex, and understanding them is merely the first step to implementing them. In this class, we learned how to write an operating from scratch on the popular handheld computer Raspberry Pi. Previous courses at Stanford like CS107 and CS110 teach topics like processes, memory, and file systems, but this class delves deeper by teaching you how to implement these features from the ground up. In addition, this class does this using the Rust programming language.
A major goal of this class is to understand the inner workings of an operating system: to not only know which gears it contains but to also understand how to turn those gears. Let’s take a closer look at the mechanics of the operating system we built in this class.
Trustworthiness: Reinforcing Safety with Rust
We can loosely define an operating system as an abstraction layer over hardware that offers protection, portability, resource management, and multitasking. Applications layer over the OS, which layers over the hardware. In order to build an operating system, we need a programming language that is up for the task. In this class, we use the Rust programming language to implement an operating system on the Raspberry Pi 3. Rust is an open source language created by Mozilla that excels in speed, parallelism, and safety. Rust offers a level of memory safety that is unmatched when compared to languages like C. C makes it very easy to make mistakes that put the security of a system at risk (for example, via memory manipulation errors). A C memory bug can cause a crash much later in a program than the originating source of the bug, which can make debugging a painful process. Rust, on the other hand, has unique properties like lifetimes, ownership, and mutability rules that encourage safer code by preventing data races, null pointers, and dangling pointers. Because of Rust’s good performance and security benefits, the language is used to create many applications ranging from gaming engines to operating systems.
Safety is one of the paramount features of the Rust language. Rust considers code to be either safe or unsafe. By “unsafe”, Rust doesn’t mean that the code is definitely unsafe; it simply has the potential to be but Rust has no way to verify the safety of such code. Thus programmers must take great care to do the proper thing when writing unsafe code. Examples of unsafe code include dereferencing raw pointers and calling unsafe functions. Rust enforces using the unsafe keyword to denote unsafe code, as shown in the following function:
unsafe fn houston() {
// we *may* have a problem…
}The concept of “safe” versus “unsafe” is very nuanced, however; if all of your code is safe and compiles, then it is guaranteed to be safe, which is pretty amazing when you compare it to a C program that compiled just fine but may have all kinds of nasty security bugs waiting to surface. A downside to the robustness of the Rust compiler is that the compiler is very picky, and rightfully so; a thorough, intelligent compiler encourages less error-prone code (though it can’t guarantee it!).
Why even support unsafe code, you ask? Unsafe code is still necessary when writing low-level code that requires an intimate relationship with the hardware. A kernel, for example, cannot be written without unsafe code. Another nice safety guarantee that Rust provides is that if there is any unsafe behavior (e.g. a memory issue), it is definitely going to be in the unsafe parts of the code. It is imperative that code is memory safe, especially for something as powerful and important as an operating system. Rust’s safety guarantees thus make the language perfectly suited for the onerous task of writing an operating system. To showcase some of the safety features of Rust, we’ll briefly introduce ownership, mutability, and lifetimes, all of which are major features that help shape the unique personality of the Rust language.
The idea of ownership is that there can only be one owner for any given resource. One major benefit of this is that it is not possible to free a resource more than once. Let’s look at a C example where this scenario is possible:
int *ptr = malloc(sizeof(int));
*ptr = 2;
free(ptr); // ptr is now a dangling ptr
When free is called, ptr stores an address. If we were to call free again on the same pointer, the program would have undefined behavior, including crashing. In Rust, this kind of behavior can be prevented in safe code.
In Rust, when we pass variables by value or do an assignment of variables whose data is transferred and not copied, the ownership moves from the original source to the destination being assigned to or to the function or method that receives the value as a parameter. In Rust, this transfer of ownership is known as a move, and it prevents the previous owner from using the moved resource which in turn prevents the creation of dangling pointers. When the owner of a resource goes out of scope, then the value it owns will be dropped.
If we don’t want to take ownership of a resource, we can instead borrow it. In Rust, we can use borrowing to instead pass resources by reference (a reference to some object T in Rust is denoted &T). References allow safe pointer usage and can be checked by the compiler.
In Rust, data is immutable unless declared with the mut keyword. In order to mutably borrow mutable data, a mutable reference is used (denoted &mut T). For any resource, you can either have one mutable reference and no immutable references, or n immutable references and no mutable references. This prevents a slew of memory issues, including data races.
Lifetimes are a way to determine the validity of references over the course of code execution. All references in Rust have lifetimes; they all have a creation time and a drop (destruction) time. Lifetimes help prevent memory errors by avoiding dangling pointers.
Let’s look at an example that covers these concepts:
fn print2<'a,'b>(x: &'a i32, y: &'b i32) {
println!("x = {}\ny = {}", x, y);
}
fn consume_string(s: String) {}
fn main() {
let x = 1; // lifetime 'a
let mut z = 2;
{
let y = 3; // lifetime 'b
print2(&x, &y);
let _r = &mut z;
}
let _r2 = &mut z;
let s = String::from("hello");
consume_string(s);
}In this example, x is in scope for the entire main function, but y is only valid within the scoped section that it is defined in. Trying to access y outside of this scope would result in a compiler error. The print2 function borrows two immutable references to integers, which both have different lifetimes. Notice the mutable variable z. Inside of the scoped block, we take a single mutable reference to z. Since this mutable reference goes out of scope once the block is over, _r2 can then take another mutable reference to z. Lastly, the consume_string function takes ownership of the string passed to it and does nothing more than dropping the string when the function returns. After dropping the string, we can no longer access s; the Rust compiler would complain because s was moved.
Now that we’ve got some groundwork on Rust, let’s see what we used it for in this class: raising and training our very own operating system!
The Personified Operating System
In this class, creating an operating system from scratch helped me think of my budding operating system as someone I try to raise to be responsible, mature, and helpful: an OS who tries very hard to always do the right thing. The way my OS turns out is a huge reflection on my ability to create, mold, and teach it how to behave as desired. It has to start somewhere, though, and our first task in class was to understand the hardware and then write code to light LEDs on a breadboard (fascinating stuff!). We learned how Rust works since that is the chosen language that formulates the brain of our OS, and we learned how to manipulate the electrical signals of the Pi. Now let’s understand how we develop the mind of the OS: it needs to learn how to process and store memory.
Memory Lane
We as people make use of both short- and long-term memory, and our operating system is no different. Let’s talk about the two major areas of memory and see how the operating system makes use of them.
A Fleeting Memory
Temporary memory is represented by the RAM of the computer, and there are two types. Some data lives on the stack; other data lives on the heap. A variable that is defined within a function, for example, lives on the stack. This kind of memory is handled automatically via function calls and returns. Because this data is transient in nature from one function call to another, we need another way to store data that persists across a call. This is where the heap comes in. Dynamically created data like strings live in the heap. Heap memory typically needs to be managed by the programmer via alloc and dealloc calls, which are serviced by a memory allocator. We implemented two types of allocators for our OS: a bump allocator and bin allocator.
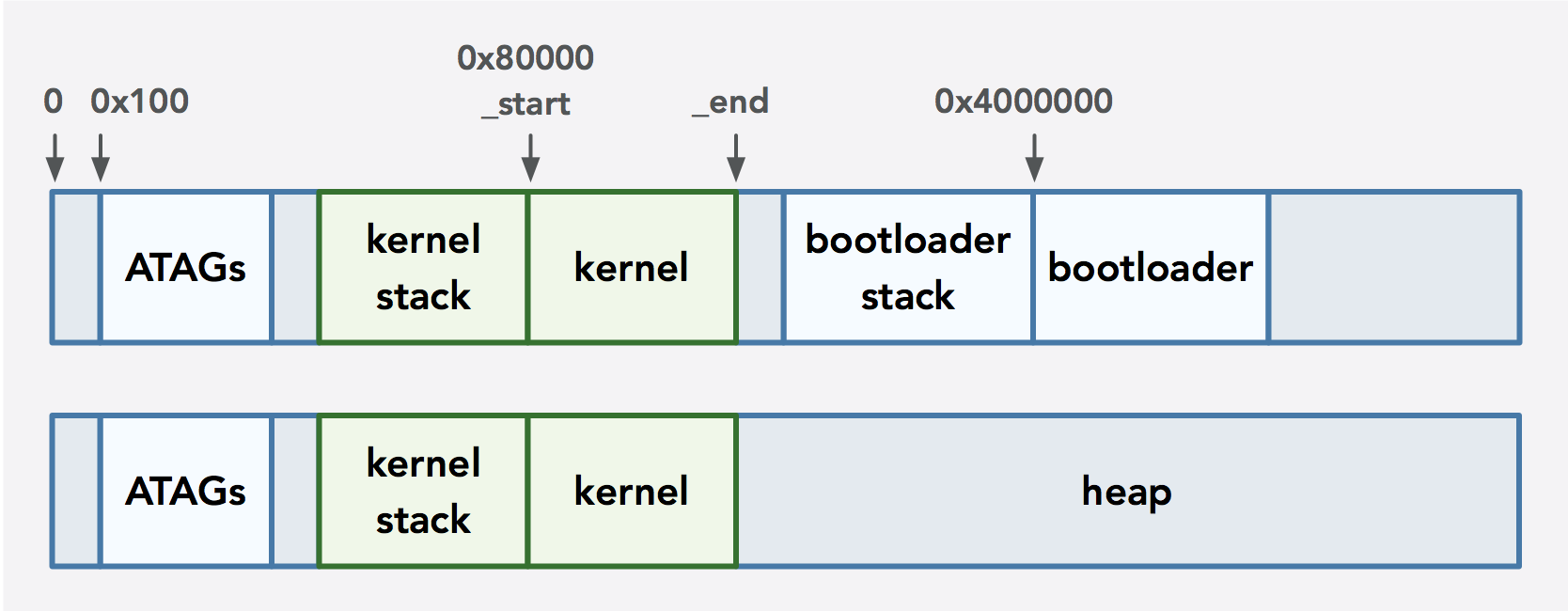
Before describing the details of these allocators, let’s first understand how the RAM is utilized on our Pi when booted. The Raspberry Pi 3 has 1GB of RAM, a small portion of which is dedicated to the GPU. The remainder gets used by the CPU. The diagram above shows what happens to the CPU’s dedicated memory space when the bootloader is loaded into memory via the Pi’s firmware.
Starting at address 0x100 in memory are ATAGs, which are ARM tags (the Pi uses the ARM architecture) that store information about the system and are loaded by the Raspberry Pi’s firmware. We use the ATAGs to get information about how much of the total RAM size is dedicated to the CPU; this will be the free memory that we can use for the heap. Once the Pi is booted, the firmware checks special files that store information about where to load the initial binary, which is our bootloader. The bootloader, in turn, uses the XMODEM protocol to receive serial data from a computer via a UART cable, and this data is our actual kernel that is loaded at a particular address in memory. Once the kernel is loaded, the bootloader jumps to the start of the kernel. Since the bootloader is no longer needed, its memory becomes part of the heap that starts after the end of the kernel (the _end label in the previous diagram) since it is no longer needed.
You may wonder what the _start and _end labels actually are for. The labels are related to linking. When the Rust compiler translates the code into object files, the object files have placeholders in it where the function calls and the addresses of global variables will eventually go. These placeholders are called symbols, and each object file has its own symbol table. Each object file can also refer to the symbols of others. Since many files can be scattered across different libraries, there’s no way for the compiler to fill in these gaps on its own. This is where the linker comes in. A symbol table assists with the mapping of the appropriate addresses. Symbols are necessary in order to let the linker know which symbol to map to which address. Then the linker combines all the object files into a binary.
The linker may have different behavior depending on the language it compiles. For example, mangling of function names occurs in Rust whereas mangling is not a concern in C. We can also give the linker specific instructions via a linker script. For example, when we load our bootloader onto the Pi, we want to specify the exact address in memory to load its binary. We can also use labels to represent specific sections of memory. For example, we use the label _start to represent the starting address where a binary will be loaded, and the linker updates the _end label to be the address of the end of the binary in memory. This is how we control where the bootloader and kernel will be loaded into memory. This _end label, in fact, is a static variable in a Rust allocator file; it is updated by the linker and used to calculate the size of the heap. Cool!
Now we can talk about heap allocators and types of implementations. A heap allocator is used to handle requests for memory that needs to persist beyond a function call. A request for a particular payload size is made, and the allocator returns a pointer to an address in memory that can accommodate the size. Allocators typically support deallocating memory when the memory no longer needs to be used. In general, we want heap allocators to be fast, provide high throughput, and strive for low fragmentation (where unclaimable chunks of memory are scattered throughout memory). Addresses also typically need to be aligned; for example, the AArch64 architecture of our OS requires the stack pointer to be 16-byte aligned. In our allocator design, allocation requests are aligned to powers of two for convenience.
Perhaps the simplest kind of allocator to discuss is a bump allocator. When a memory allocation request is made, the allocator gets a pointer to the beginning of the remaining free space (which initially starts at the beginning of the heap) and bumps it up by the requested allocation size plus the number of bytes necessary to fulfill the alignment request (note that this alignment value must be provided in Rust allocators). Thus the allocator starts with a large slab of available memory and simply cuts it down in size whenever an allocation request is made. This happens until memory runs out. Note, however, that bump allocators don’t support deallocation, which will leak a lot of memory and cause memory to fill up much faster since space is not reused. This is what makes the design of this allocator so simple: without deallocation, we only need to keep track of the address of the start of remaining free memory. Thus we gain speed, high throughput, and tight utilization at the expense of effective memory use.
Here’s an illustration of what happens when two allocation requests are made using a bump allocator:
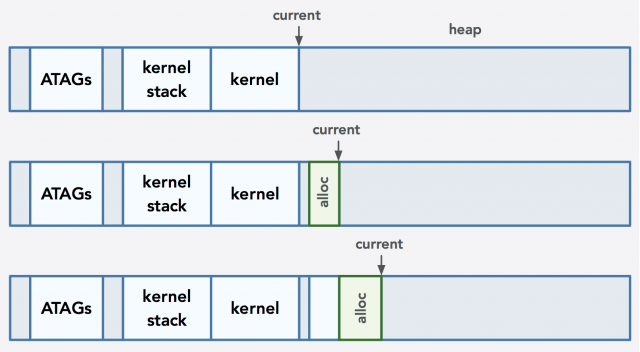
In the middle memory state shown above, there is a gap between the end of the kernel (which is the initial starting point of the heap) and the address returned to the caller. This scenario implies that the end address of the kernel is not aligned as necessary, so the address is aligned up and then the current pointer (which keeps track of the start of the remaining space for the heap) is set to that aligned address plus the payload size. In the third state, the current pointer is already aligned and then the payload size is added to it to prepare for the next request. Because of alignment requirements, our bin allocator does introduce some external fragmentation.
A bin allocator, on the other hand, is much more sophisticated and can be implemented in many ways. The general idea is that allocations are made by finding an appropriately sized bin in a list of linked lists that store free memory blocks differentiated by size classes. In my particular implementation, for example, the bins were based on ranges of powers of two (in Rust, the pointer returned upon an allocation must be a power of two): for example, I had blocks of memory ranging in size from 16 bytes to up to 32 bytes in one bin, and blocks ranging from 32 bytes up to 64 bytes in another bin. By having size classes, allocations are made by finding the appropriate block size and ensuring alignment rules are met.
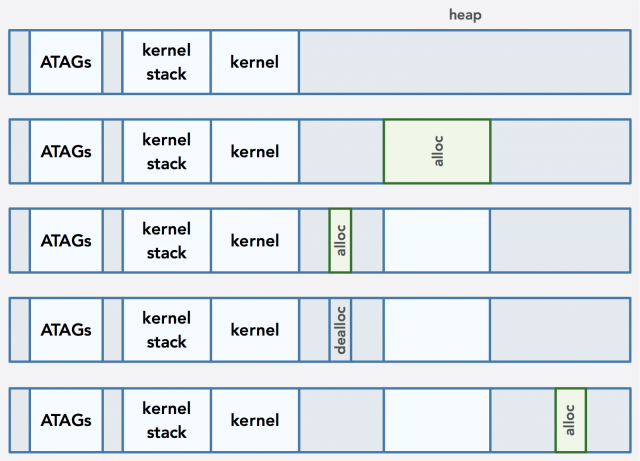
We can enhance a bin allocator by splicing off any free space before and after a payload and putting it back into the list of free blocks, which decreases fragmentation.
Other implementations of an allocator may opt to not splice off extra space. This would increase fragmentation but simplify the implementation. Some implementations may also use a header that is stored in memory for each free block in order to determine the exact size of the block that can be allocated. Pointers that are returned to the caller would also be preceded by headers in order to determine exactly how much space to recycle upon deallocation. This approach is more complex but drastically helps reduce fragmentation. Other designs may reduce fragmentation further by coalescing contiguous free blocks.
Here’s a general example of how a bin allocator would handle allocations and deallocations:
In Rust, we can get heap allocated memory by creating a vector, string, or box. One thing worth mentioning is that unlike languages like C where alloc and dealloc calls can be done explicitly, Rust implicitly handles memory for us in some crucial ways. Rust enforces RAII (Resource Acquisition Is Initialization), so when a resource goes out of scope, its drop function is automatically called which deallocates memory and in turn prevents resource leaks. A drop function in Rust simply takes ownership of a resource and returns, which causes the resource to go out of scope. The consume_string method in the code example explained earlier is an example of a drop function.
Virtual Memory
Although we haven’t yet implemented virtual memory on our OS, it is a fascinating and prevalent feature that is worth discussing. Virtual memory gives processes the illusion that they have private, exclusive access to a large address space. For example, on a 64-bit machine, each process could theoretically address 264-1 bytes of memory (although this number is actually 248-1 on our Pi since ARMv8 only supports 48 bits of virtual address). Virtual addresses are used by users, the compiler, and the linker, whereas physical addresses are directly used by the hardware. In reality, though, the actual available memory is limited to a particular portion of the RAM. Virtual memory protects processes from each other; the addresses used by one process are isolated from other processes. Processes have no idea that their addresses are virtual.
The OS manages the mapping between physical and virtual addresses with help from the MMU (memory management unit), TLB (translation lookaside buffer, a memory cache that is part of the MMU), and page tables (which are data structures that (physically) store the mapping between virtual and physical page numbers, which in turns means they store the logical mapping between virtual and physical addresses). When a virtual address needs to be translated to a physical address (for a read or write), the MMU does a lookup, which will first check the TLB for a cache entry for the virtual address. If an entry is found, the physical address is passed back to the kernel. Otherwise, the MMU does a page table walk to find the mapping, which is then cached in the TLB and the physical address is returned. Thus the TLB reduces the time it takes to access a physical address.
One may wonder why we even bother to have virtual memory in the first place. It turns out it is an important feature that prevents a lot of issues. Without it, processes would have to coordinate which process uses which subset of addresses at any given time. One major concern is a situation in which different binaries have functions that have the same hardcoded addresses. It would then be impossible to load the programs into memory and run them at the same time since these programs could have such functions try to load the same memory address simultaneously. As another example, if all processes share the entire physical address space, it is possible for a process to read potentially sensitive data from another process by accessing a well-guessed physical address.
Making It Stick: Persistent Storage & File Systems
Now that we have a grasp on memory, let’s talk about something more persistent: hard disk memory. Hard disk drives are the main form of persistent data storage, comprised of areas that can be read or written. Persistence is the key differentiating factor when comparing RAM to the hard drive: RAM doesn’t retain information on reboot whereas persistent storage devices can permanently store data.
This brings us to file systems. A file system is used to organize and bookkeep the data on a disk. It organizes the storage and retrieval of the data and provides two main abstractions: files and directories. Think of directories as nested folders that store pieces of information (files) and metadata about those pieces of information. A file is a collection of bytes that resides within a directory (in contemporary file systems, a directory is really just a special file).
In this class, we implemented a popular file system called FAT32 (FAT for file allocation table, which is key to the way data is stored on disk). FAT32 is known for its cross-platform support. Disks can be partitioned, and each partition can, in turn, be formatted for a different kind of file system. In order to know where on disk the partitions are located as well as know important bookkeeping data associated with each partition, a partition scheme is used. In this class, we use a master boot record (MBR) which is located in the first sector on the disk. We use it to store the information for a FAT32 partition on an SD card on the Pi.
At the beginning of the course, our OS could do very little until we implemented a shell that could only do what children do best: play copycat via the echo command. Our OS clearly started off in a rudimentary phase, but this is the start of something beautiful: an OS that can follow commands. And well-behaved operating systems are beautiful things! Once we implemented a file system, we added commands to our shell to have it print what’s in the current directory, change directories, print the contents of a file, and more. Our OS is growing up so nicely!
Playing Well With Others: Device Drivers
Now that our evolving operating system is in a memorable state, we want to ensure that it knows how to effectively interact with other elements. Enter device drivers. Device drivers allow operating systems to interact with a wide array of devices by abstracting away the details of the hardware. They serve as a bridge between the software (in our case, the operating system) and the hardware. Different drivers serve different purposes; for example, in this class, we wrote drivers to manipulate GPIO pins on the Pi and utilize the built-in timer. As another example, we used a UART driver to transfer data from our computer to the Pi via a UART cable using the XMODEM data transfer protocol. The bootloader is loaded from the Pi’s SD card into memory by the Pi’s firmware, and a ttywrite utility sends the bootloader the kernel binary, which the bootloader then executes after loading it into memory.
As the core of the operating system, the kernel is able to interact with hardware through device drivers; this provides isolation and security. User code does not interact with hardware directly; instead, it indirectly communicates with hardware via the system call interface of the operating system (more on this later).
Adulting 101: Multitasking and Scheduling
At this point, our OS is capable of running some commands in a shell and reading files from the SD card, but since we only set up one core to do any work while the other three sleep, our OS can only run one process at a time. Before we discuss how to fix this issue, let’s discuss what processes actually are. A pattern should have emerged by now: a majority of the concepts related to operating systems involve abstractions, and processes are no exception. We are all familiar with the concept of running a program on our computers. The program itself is a bunch of code neatly packaged and tied with a pretty bow, but running the actual program is done in the context of a process, which we can think of as an instance of a program. Processes allow programs to run in isolation of each other. Since each process gets its own virtual address space, there is no risk of the data of one process being accidentally shared with another process. In addition, this ensures that if one process crashes, the others won’t go down with it. Perhaps the major benefit that processes provide is their role in multitasking. Since processes can take turns getting processor time, they allow users to believe that multiple processes are running at the same time, which provides the illusion that there are multiple CPUs at work when that is not the case at this point on our Pi (we only have one hard-working core).
In our operating system, a process is defined as a struct that stores pertinent information about the data and the state (the context) of a process at any given time. This is akin to storing process control block (PCB) data. We store the process’ heap-allocated trap frame (which contains the processing context which stores pertinent register data), stack, and state. The state conveys whether a process is ready, running, or waiting, as shown in the diagram below.
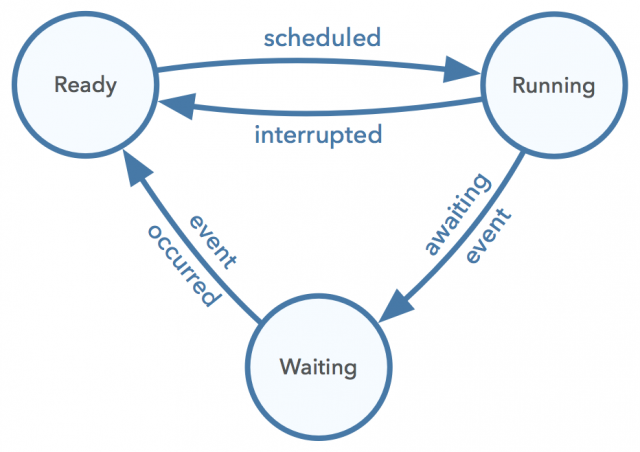
A user process gets a particular amount of memory allocated for its stack. In our system, each process starts with 1MiB of memory. At this point in our OS, this abstraction allows us to call particular functions that run as a process and execute for a period of time before being swapped off the processor so that another process can run. In a fully functional system, processes are created by loading the code and data of a program into memory and creating the stack, heap, default file descriptors, and other I/O-related setup and bookkeeping information. The process then begins execution by jumping to a particular location in memory (usually the main function). Our OS is limited in functionality but the same abstractions apply.
The aforementioned cycle of letting a process run for a certain amount of time before deciding which process to run next is called scheduling. A scheduler determines how long a process should run for (a length of time known as a quantum) and which process should run next. The scheduler performs a context switch that involves stopping the currently running process, saving its data so it can be restored later, getting the next process to run from a queue, and restoring the next process’ data. Context switching is a property of preemptive schedulers that determine when to stop the execution of a process and decide what happens next. This is in contrast to non-preemptive schedulers, which run each process to completion before running the next one.
There are many types of scheduler implementations, each with their list of pros and cons. Examples include first-come-first-serve and priority-based schedulers. Good schedulers encourage good turnaround time of processes (where processes finish in a respectable amount of time). Good schedulers also strive to have good response times so the system doesn’t appear unresponsive. Bad schedulers make poor decisions regarding the scheduling of processes, have inefficient quantum times, and cause an imbalance that results in processes having a long turnaround time. It is worth mentioning that finding the right length of time for the quantum is important because if the time is too short, context switching becomes an expensive operation, but if the time is too long, then the system appears to run slowly.
In this class, we implemented a round-robin scheduler, which features a time-slicing method that uses a quantum to determine the maximum amount of time to run each process before saving its data and running the next one. It uses a queue to store all the processes, and if the next process to run isn’t ready to execute, it is put at the end of the queue and the next process is considered. Thus the scheduler continuously loops through the processes until they are finished (although our current OS doesn’t have a notion of processes finishing yet).
In order to have a quantum be meaningful, the system timer driver is used to implement a timer that sends an interrupt whenever it is time for the scheduler to stop one process and start another. Let’s briefly discuss what exceptions are and how they relate to interrupts.
Pardon The Interruption
Exceptions include faults, traps, and aborts that handle certain behavior. Interrupts are used to handle external events. Interrupts and exceptions can communicate information and provide context switches. Exceptions are crucial to understanding the privileges of a system. When an exception occurs, the CPU executes handler code specific to that exception. For ARM, this handler code is stored in an exception vector table that contains the appropriate instructions to execute (each exception level has its own table).
On the Pi’s ARMv8 architecture, at any given time, the processor executes at a specific exception level. There are four total exception levels on our system, and each level represents a different privilege level: the higher the exception level, the higher the privilege. For example, exception level 0 represents the user space (where user processes are run) and exception level 1 represents the kernel space. The CPU on the Pi boots into exception level 3 which loads the Pi’s firmware, which in turn switches to exception level 2 to run the kernel binary. In our OS, we wrote assembly code to execute our kernel in exception level 1 and then set up the user space to run in exception level 0. This isolation is important in order to maintain protection of what can run certain code. System calls, for example, that are made in the user space actually run in the kernel to avoid security concerns. System calls, such as open, read, and write, are unidirectional function calls that provide protection between the user space and the kernel. They are instructions that the processor understands on a very low level. Interrupts and traps can be used to implement system calls.
To wrap up our discussion of processes, let’s see how processes communicate with each other. Processes can share data via inter-process communication (IPC). Different IPC methods include signals, regular pipes (which I wrote about extensively here after taking CS110 last quarter), named pipes, sockets, and shared memory. IPC is valuable because it allows processes to behave cooperatively and share messages with each other without compromising the isolation of sensitive process data. It also provides a way for processes to stay in sync, which brings us to our last topic: synchronization.
Staying In Sync
Although we didn’t handle concurrency in our OS, it is important to understand the challenges that arise when trying to keep data in sync across cores. Synchronization is an ensured ordering of events across potentially concurrently executing code. The Raspberry Pi 3 has four cores, and each core has caches (for example, an L1 instruction cache, L1 data cache, and L2). RAM sits outside of the CPU and it is relatively expensive to access memory from it compared to the speeds of accessing data from the CPU caches, which is why caches are so valuable.
When caching is supported, we gain the ability to quickly look up information, but the tradeoff is that we also lose the ability to always see data reads and writes in the same order since caches need to be synchronized across cores. Because caches are private per core, the changes in one core’s cache are not automatically visible to other cores. This causes data incoherence across the cores. In order to guarantee the order in which things happen, we need to introduce a few new concepts.
First, let’s understand how caches store and retrieve data. Cache lines are data blocks that store data read from an address in memory in the cache. Each cache entry contains three parts: a tag (which is a memory address), the actual data, and flag bits. When the processor needs to access data in memory, it will first check for the appropriate cache entry. If there is a cache hit, the processor reads or writes the data in the cache; otherwise, a new cache entry is created with the appropriate data from memory and then the read or write happens on this cache data. Thus all memory accesses are really a cache line at the lowest level.
This brings us to cache coherence, which is a set of protocols for keeping cores up to date with changes in shared data. This helps avoid inconsistent data via synchronization, which maintains data integrity.
Let’s illustrate an example that doesn’t utilize cache coherence. Imagine a system that has three cores A, B, and C. Each core starts off with the same cached copy of some shared data X. Say core A comes along and changes its cached copy of X to be 100 while core B changes its cached copy of X to be 2. It is possible that core C will see the changes made in one of the two possible orderings, and depending on the perspective, core C may read the value of X and get either 2 or 100. This causes C to have an incoherent view of the shared data. Cache coherence can fix this problem by providing a way to ensure that the sequence in which writes to some shared data occur is consistent and communicated to the cores.
Local updates to cache data are invisible to other cores. One way we can achieve cache coherence is to use a protocol like MESI to allow other cores to know when updates have been made to shared data. If cores share data and a value is stored in multiple data caches and one core changes it, then the data needs to be updated everywhere else. The name “MESI” is an acronym where each letter represents a different state that a cache line can be in: modified, exclusive, shared, and invalid.
If a cache line is modified, then it only exists in the core that has changed the entry, and only this core can continue to access the entry. A modified cache line is akin to a mutable reference to a resource in Rust. If a cache line is exclusive, then it also only exists in the core that has read the entry but the entry data is currently clean (meaning it is the same in both the cache and memory) and there is exclusive access to the entry. If a cache line is shared, then it cannot be written to since it may also exist in other caches. Its data entry is clean. We can think of a shared cache line as being one of many immutable references to a resource in Rust. Lastly, if a cache line is invalid, then it doesn’t contain a valid entry and is unused; this is the starting state of all cache entries.
As changes are made to the data in a cache entry, the MESI protocol ensures that access is synchronized. By keeping track of the state of cache lines, MESI provides cache coherence. Cores stay up to date via snooping, which broadcasts all reads and writes for a cache entry in all cores. MESI is a way to achieve TSO (total store ordering, a specialization used by Intel), which is a weak memory model that allows the processor to optimize reads and writes to and from caches. TSO assures that all cores will see writes in exactly the same order. With these mechanisms, cache coherence is achieved while simultaneously allowing the processor to achieve a certain level of optimization.
Not Quite All Grown Up
Although our operating system is pretty impressive considering where we started at the beginning of the class, there is still a lot of opportunity for growth. We still need to implement virtual memory, for example, to make our OS more robust. However, we accomplished a lot in ten weeks considering that this was the very first offering of this course. We’ve only scratched the surface of how powerful and important operating systems are. I hope to continue learning Rust and developing my operating system into an “adult” phase. I am so impressed with the knowledge I gained in this course and I’m blown away by how good the assignments were. Kudos to the entire teaching staff for a job well done!